
Orion-100B Macrocosmos: 100B Model Trained Over the Internet
Macrocosmos has launched the first stage of Project Orion, and the early results redefine what distributed AI training can achieve. The team behind Bittensor IOTA SN9 trained Orion-100B, a 100 billion parameter model running across globally distributed single GPUs over the public internet. The team calls this the largest distributed large language model pretraining run ever conducted over the open internet. It arrives with a claim that should grab the attention of every AI lab watching compute costs climb.
The headline number is striking. Orion-100B Macrocosmos reached roughly 65% of the training speed of an equivalent datacenter setup. Yet it ran on hardware that costs a fraction of the price. For an industry that treats billion-dollar datacenters as the only path to frontier models, this marks a genuine inflection point. The run shows that underutilized compute scattered around the world can become real frontier training capacity.
What Orion-100B Macrocosmos Actually Achieved

Orion-100B Macrocosmos was an early pretraining run on a 100 billion parameter model. It used a modified Llama-3.2 architecture. The team sharded the model across 16 pipeline-parallel stages with 3 replicas, totaling 48 devices. Each stage ran on a single Nvidia A100 80GB GPU hosted by a non-colocated peer. These peers sat across five datacenters within the United States. Multiple providers supplied the GPUs, with median upload and download speeds of 856 and 1322 mbps. Those figures reflect ordinary commodity internet rather than specialized interconnect.
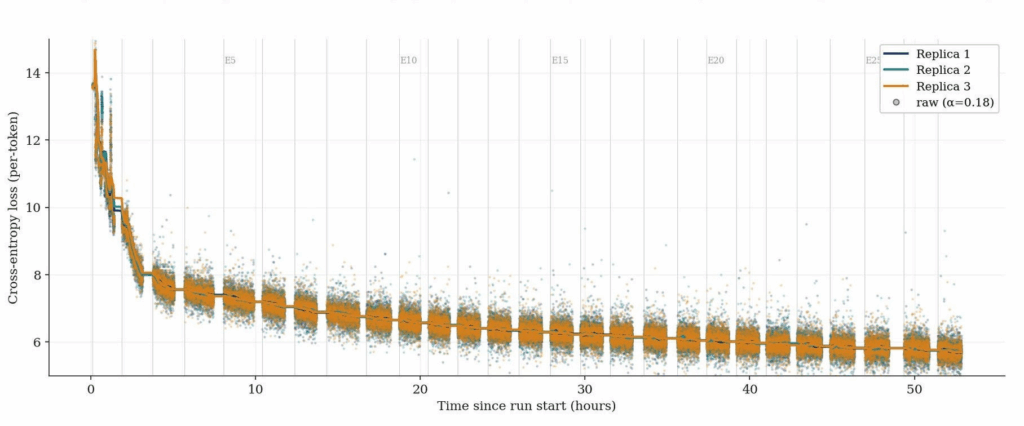
The run trained for roughly 1.1 billion tokens of the fineweb-edu-score-2 dataset. It lasted about two days before the team stopped it for cost reasons. Throughout training, the system sustained an average Model FLOP Utilization (MFU) of 30.8% on the A100 chips. The peak sustained MFU hit 38% over a six hour window without churn. Average system throughput sat around 9000 tokens per second. Macrocosmos states that no distributed pipeline-parallel training run has ever reported a higher MFU.
The efficiency figures translate directly into competitive training speeds. The 30.8% average MFU equals training roughly 65% as fast as co-located devices with high bandwidth interconnect. The peak sustained figure reaches 82%. Orion-100B also hit overall training utilization of 81.8%. That number matches the earlier INTELLECT-1 run while training a model ten times larger.
The Architecture Behind the Breakthrough
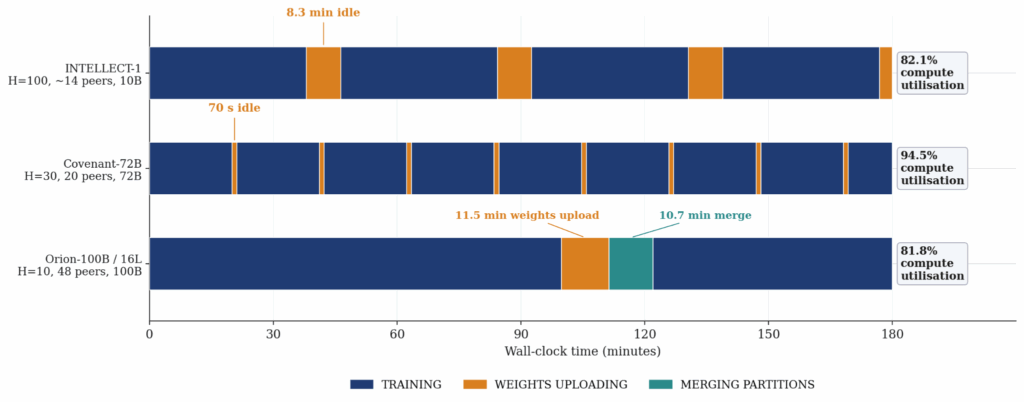
The core idea separating IOTA from earlier decentralized training efforts is its choice of parallelism. Most prior projects used distributed data parallelism, where every peer hosts a complete copy of the model. INTELLECT-1, Psyche Consilience, and Covenant-72B all took this route. That approach works, and Covenant-72B proved it at impressive scale. Yet it carries a structural ceiling. The memory of the smallest peer bounds the largest model a data-parallel network can train. Covenant peers needed eight B200 GPUs each at roughly $50 per hour.
IOTA took the harder path of distributed pipeline parallelism. It splits the model itself across peers, so each one hosts only a fraction, sometimes as little as a single transformer block. Total model capacity then scales with the combined memory and compute of the entire network rather than the limits of any single machine. This design lowers the barrier to entry dramatically and lets the network grow one GPU at a time. The tradeoff is a far harder engineering problem, because the system becomes deeply entangled once the model spreads across peers.
Three technical advances made the result possible. The first is ResBM, currently the state-of-the-art technique for lossless activation compression in LLM training. ResBM cut the native dimension of hidden activations by 64 times. This shrank the activation data moving between pipeline stages from 140.6 MB down to 2.2 MB. The second is a custom fault-tolerant peer-to-peer networking protocol that optimizes throughput and latency across heterogeneous GPU nodes. The third is reliable distributed variable synchronization through the IOTA Bridge Service. Together these advances increased IOTA training speeds by an order of magnitude since the project began.
A Year of Quiet Iteration
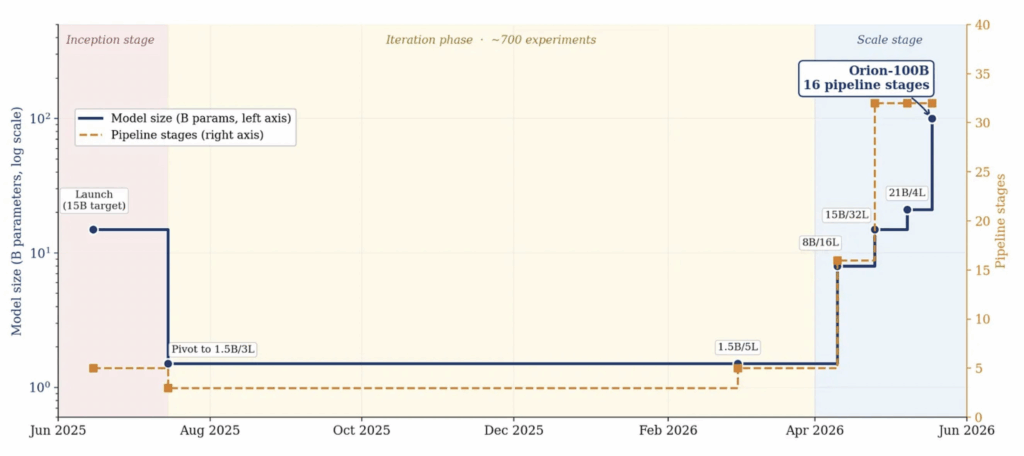
The path to Orion-100B Macrocosmos ran through a deliberate and unglamorous strategy. Work on IOTA began in April 2025. The team launched in June 2025 with an ambitious 15 billion parameter target split across five pipeline stages. The system collapsed almost immediately under a mix of system overload and adversarial attacks. The upfront complexity proved overwhelming.
Rather than push harder on scale, the team reduced it. In July 2025 they switched to a small 1.5 billion parameter testbed with three layers. It was small enough to train quickly yet complex enough to teach the important lessons. Between August 2025 and April 2026 they ran over 700 controlled experiments on that testbed and trained for nearly 15 trillion tokens. They rebuilt every part of the codebase and infrastructure along the way. The goal was to de-risk the system rather than produce a useful model. Over that period, throughput climbed by roughly an order of magnitude.
By April 2026 the system was ready for larger models. Macrocosmos scaled model size by 67 times and pipeline stages by 10 times in a single month. The team validated the architecture across more than 750 experiments spanning 1.5 billion to 21 billion parameters. Then they launched the full 100 billion parameter Orion run.
The Economics That Change the Calculation
The most consequential property of the Orion-100B Macrocosmos run is its cost structure. A Covenant-class peer running eight B200 GPUs costs roughly $50 per hour at mid-2026 cloud market rates. An Orion replica built from 16 non-colocated A100s at $1.25 per hour each costs as low as $20 per hour. That works out to a 2.5 times lower entry cost. Individual peers can join the network for as little as $1.25 per hour, a figure that aligns closely with the decentralized ethos Macrocosmos pursues.
There is also clear headroom for further efficiency. The Orion run used only about 10 inner steps before synchronizing, a conservative choice that favored stability. Raising that to 100 inner steps could push overall compute utilization to 97.8% with no expected hit to model quality. The team also skipped pseudogradient compression schemes such as DeMo or SparseLoCo during this run. They expect that even modest compression could cut synchronization time to less than 0.5% of total training time.
Where Project Orion and Orion-100B Macrocosmos Go Next

The team ran Orion-100B as a system-viability proof. It set out to answer whether the pipeline-parallel approach with ResBM compression works at hundred billion parameter scale. With roughly 750 experiments, four scaling steps, and the Orion results in hand, Macrocosmos believes the answer is increasingly yes. The run is the opening move in a broader programme that will progressively relax the constraints of the current setup.
The roadmap advances through four stages. First, the team will introduce heterogeneous hardware to blend different GPU generations and tap into stranded, underutilized compute. Next, it will move to interruptible spot-market instances available at discounts of up to 90%, which IOTA can use thanks to its fault tolerance. After that, it will open the network to permissionless untrusted contributions and remove the final centralized pillar. Finally, it will onboard consumer grade machines such as RTX 4090, 5090, and Apple M Series devices. This step builds on the existing Train at Home swarm already live on Bittensor.
For the wider Bittensor ecosystem, the implications run deep. SN9 has long served as the proving ground for IOTA. Macrocosmos credits the network’s scale, adversarial permissionless setting, and capable community for hardening the architecture under real operating conditions. If Project Orion delivers on its remaining milestones, it would offer definitive evidence that decentralized training can compete economically with centralized datacenters at meaningful scale. That result would reshape how the entire industry thinks about building frontier models.
Frequently Asked Questions
Orion-100B Macrocosmos is an early pretraining run of a 100 billion parameter language model trained across globally distributed single GPUs over the open internet. It is the first stage of Project Orion and runs on Bittensor SN9 through the IOTA architecture.
The run reached roughly 65% of the training speed of an equivalent datacenter setup, with a peak sustained figure of 82%. It sustained an average Model FLOP Utilization of 30.8% on Nvidia A100 80GB chips.
A Covenant-class peer with eight B200 GPUs costs roughly $50 per hour. An Orion replica built from 16 non-colocated A100s costs as low as $20 per hour, and individual peers can join for just $1.25 per hour.
The model trained for roughly 1.1 billion tokens over about two days. The team then stopped it for cost reasons, since the goal was to prove system viability rather than finish a full model.
Macrocosmos will progressively relax the current constraints across four stages: heterogeneous hardware, interruptible spot instances, permissionless participation, and consumer grade machines such as the RTX 4090 and 5090.


