How the Chutes (SN64) Model Router Works | Bittensor
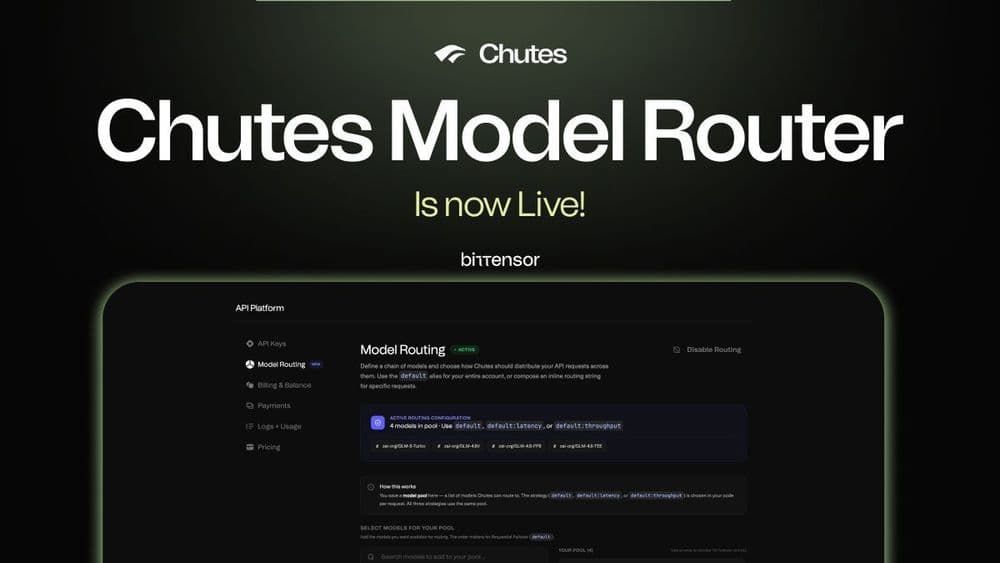
The Bittensor subnet Chutes (SN64) has introduced a major infrastructure upgrade aimed at improving how AI models are served to developers. The new Chutes (SN64) Model Router allows developers to define a pool of up to 20 models and automatically route API requests across them using a single alias.
In practice, this works similarly to a load balancer for AI models. Instead of hardcoding individual model endpoints, applications can send requests to one routing layer that dynamically selects the best available model. This approach improves reliability and reduces the risk of downtime when individual models become overloaded.
How the Chutes (SN64) Model Router Works
The feature introduces three distinct routing strategies. Developers can select each strategy on a per-request basis through the model field in any OpenAI-compatible SDK.
The first strategy is called sequential failover and uses the identifier default. It tries models in a developer-defined priority order. If the top-priority model is busy or degraded, the system automatically moves to the next one in the queue. As a result, end users never encounter downtime from a single overloaded model.
The second strategy optimizes for latency and uses the identifier default:latency. It selects whichever model currently offers the lowest time to first token. This makes it particularly useful for real-time applications where response speed matters most.
The third strategy targets throughput and uses the identifier default:throughput. It picks the model with the highest tokens per second at any given moment. The Chutes team designed this option specifically for long-form generation tasks that require sustained output.
Why Developers Need the Chutes (SN64) Model Router
Model Routing addresses a common pain point in AI infrastructure. Developers traditionally hardcode a single model endpoint into their applications. When that model hits capacity or experiences degradation, users face errors or slow responses. The Chutes (SN64) Model Router eliminates this single point of failure entirely.
The system operates on live performance data rather than static configurations. It monitors each model in the pool and makes routing decisions in real time. Importantly, developers only need to change the model field in their existing SDK setup. No additional code changes or custom logic are required.
The feature is already accessible through the Chutes dashboard at chutes.ai/app/api/model-routing. The project also maintains its open-source presence through its GitHub repository under the Rayon Labs organization.
What This Means for Subnet 64
This release fits into a broader pattern of infrastructure development on Chutes (SN64). The subnet has consistently focused on making decentralized AI compute more practical for production use cases. Model Routing adds another layer of reliability and flexibility to that stack.
The launch positions Chutes as one of the more developer-focused subnets in the Bittensor ecosystem. Rather than introducing new models, the team chose to improve how existing models get served. That distinction matters for developers who need consistent uptime and predictable performance from decentralized infrastructure.
Whether this feature drives meaningful adoption among developers outside the Bittensor community remains to be seen. However, the technical approach itself aligns with how major centralized providers handle model routing and load balancing. The Chutes (SN64) Model Router essentially brings that same reliability pattern to decentralized AI compute.


