
New AI model from Google: Gemini 3.1 Pro
Gemini 3.1 Pro is presented by Google as an incremental but technically meaningful upgrade over Gemini 3 Pro. Rather than introducing an entirely new model family, this release focuses on improving reasoning quality, agentic workflows, and structured code generation, while keeping the broader multimodal and long-context capabilities introduced in earlier generations.
This article examines what previous Gemini Pro models offered, what 3.1 Pro adds, and how the improvements show up in benchmarks and real-world use.
What Gemini Pro Previously Delivered
Earlier Gemini Pro versions established three main pillars.
First, multimodal understanding. The model could process text, images, and other inputs within a unified system. This allowed use cases such as document analysis, code review, and visual reasoning in a single workflow.
Second, long context windows. Gemini Pro models supported large input contexts, enabling analysis of long documents, repositories, or structured datasets without aggressive chunking.
Third, tool integration and function calling. The model could invoke external tools, generate structured outputs, and interact with APIs. This laid the groundwork for more agent-like behavior, but real-world reliability in multi-step tasks remained a challenge.
These capabilities positioned Gemini Pro as a competitive general-purpose model for coding, research, and enterprise use. However, performance in advanced reasoning benchmarks and multi-step agent tasks left room for improvement.
What Gemini 3.1 Pro Adds
Gemini 3.1 Pro keeps the same general capability envelope but introduces measurable improvements in reasoning and agentic execution.
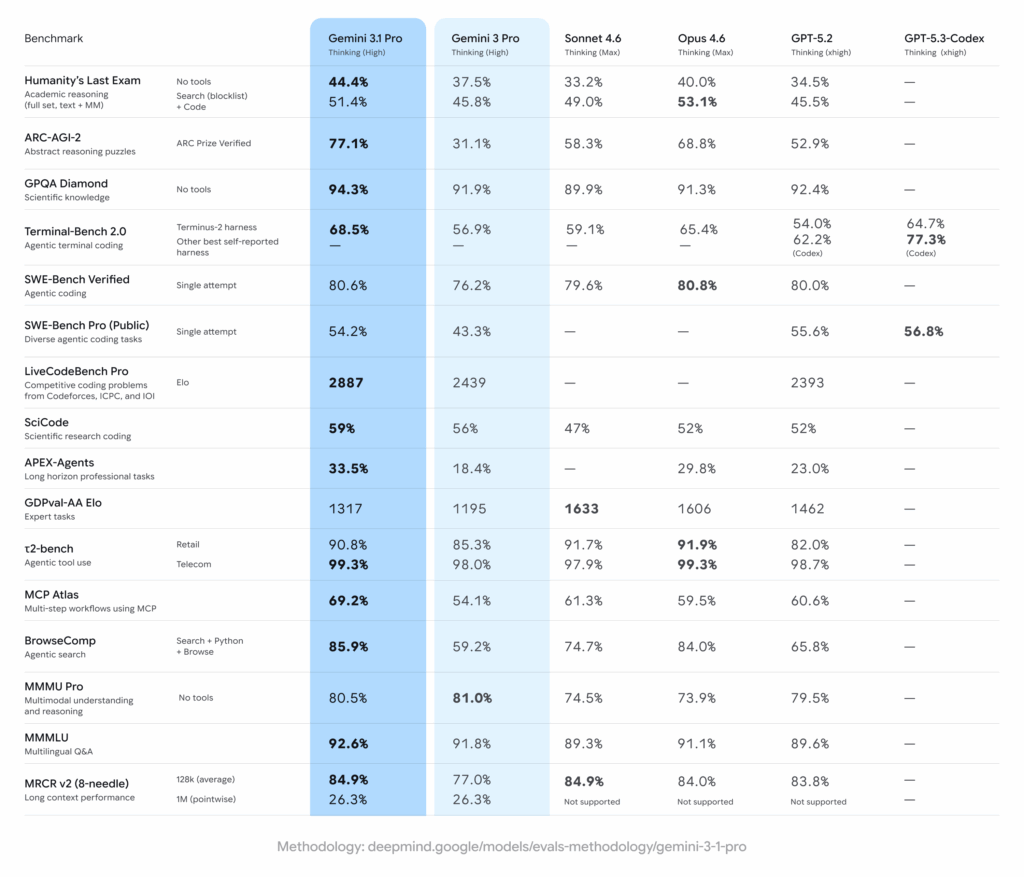
Google highlights a major jump in ARC-AGI-2 (verified), reporting 77.1% for Gemini 3.1 Pro compared to 31.1% for Gemini 3 Pro. ARC-style benchmarks test abstract reasoning and pattern generalization rather than memorized knowledge. A gain of this size suggests changes in how the model handles novel problem structures.
In software engineering evaluations, Gemini 3.1 Pro shows improvements on SWE-Bench Verified, Terminal-Bench, APEX Agents, and BrowseComp. These benchmarks test real-world development tasks, command-line workflows, and multi-step browsing with tool use. The consistent pattern is not just better text output, but better coordination between reasoning and tool execution.
Google describes this as strengthening “core reasoning.” From a technical perspective, it appears aligned with improved planning, error recovery, and structured decision-making across steps.
Improved Reasoning on Novel Tasks
The most visible change is performance on abstract reasoning benchmarks.
ARC-AGI-2 measures the ability to generalize patterns from small examples to unseen tasks. These tasks are deliberately designed to resist memorization. Gemini 3.1 Pro’s reported improvement indicates stronger compositional reasoning and pattern abstraction.
This matters beyond benchmarks. Better abstraction typically translates into improvements in areas such as: mathematical problem solving, algorithm design, data transformation logic, and multi-constraint planning problems.
While benchmark numbers should always be interpreted cautiously, the direction of change is consistent with Google’s stated focus on reasoning rather than just scaling.
More Reliable Agentic Workflows
Gemini 3.1 Pro is also positioned as stronger in agent-style tasks.
Benchmarks such as Terminal-Bench and BrowseComp test whether a model can: plan multiple steps, choose appropriate tools, execute commands, and adjust based on intermediate outputs.
In earlier versions, tool calling worked but sometimes lacked prioritization or stable long-horizon planning. Google has introduced improvements including a preview endpoint focused on better custom tool prioritization. This suggests that internal changes were made to how the model evaluates when and how to invoke tools.
For developers building AI agents, this is likely more impactful than raw text quality improvements. Agent reliability is often the bottleneck in production systems.
Large Context and Multimodal Support Maintained
Gemini 3.1 Pro continues to support up to 1 million input tokens and 64k output tokens, with a knowledge cutoff in January 2025.
The long context capability is not new in this release, but it remains central. In practical terms, this allows: analysis of entire codebases, processing long research documents, reviewing large contracts or reports, and multi-document synthesis.
The model is available across Gemini App, Google AI Studio, Gemini API, and Vertex AI, keeping deployment options similar to previous Pro versions.
SVG Animations and Code Generation: A Side Trend
One smaller but visible aspect of the launch is improved code-based animation generation.
Google demonstrated that Gemini 3.1 Pro can generate animated SVG files directly from text prompts, producing scalable vector graphics that remain crisp at any resolution. SVG generation requires correct XML structure, coordinate logic, timing definitions, and animation constructs such as SMIL or CSS keyframes.
Following the announcement, users on Twitter began sharing short demos where they test the model with prompts such as animated loaders, procedural scenes, or stylized illustrations. Some of these examples have gone viral because SVG animations are compact and easy to preview in social feeds.
However, this trend should be viewed as a byproduct of improved structured code generation, not the core purpose of the model. The real significance is that consistent SVG output implies better handling of syntax, layout logic, and multi-step construction within a single file.
Comparison: Gemini 3 Pro vs Gemini 3.1 Pro
The shift from 3 Pro to 3.1 Pro appears evolutionary rather than architectural.
Both models support multimodal input, large context windows, and tool integration. The main differences are visible in: abstract reasoning performance, agent benchmark results, software engineering task success rates, and improved coordination with external tools.
The benchmark improvements reported by Google suggest stronger generalization and more stable multi-step execution. This aligns with a refinement cycle rather than a complete redesign.
It is also important to note that 3.1 Pro is labeled as a preview in several contexts. Production adoption should consider rate limits, potential behavior shifts, and evaluation under domain-specific workloads.
Source
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/


